Designing a Production-Grade Kubernetes Platform with Terraform (Lessons from the Field)
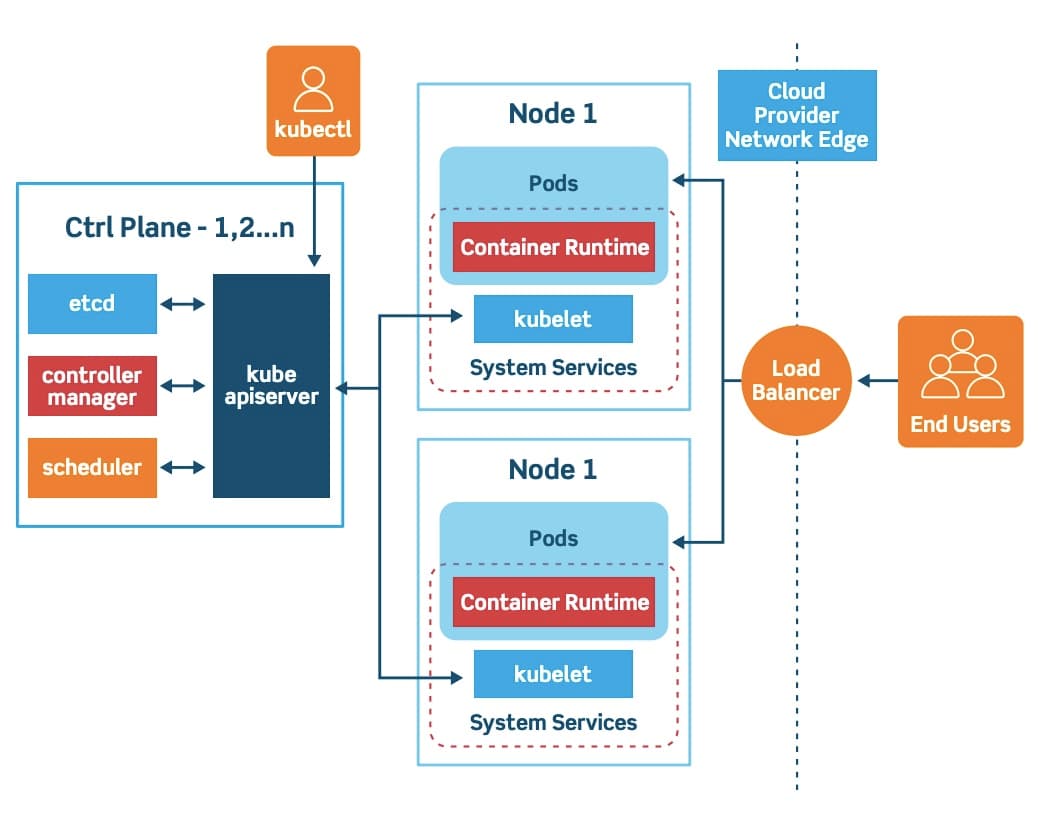
Context
At scale, Kubernetes is not a cluster - it's a platform.
The challenge isn't "how to create a cluster", but:
- How do you standardize environments?
- How do you enforce governance without slowing teams?
- How do you ensure reproducibility across regions, clouds, and time?
In this post, I'll walk through how I design Kubernetes platforms using Terraform as the control plane, drawing from real-world experience operating regulated, multi-tenant environments.
Platform Design Principles
Before writing Terraform, we establish non-negotiables:
- Everything is declarative
- No environment is special
- Clusters are disposable
- State is more important than resources
- Day-2 operations matter more than Day-0
Terraform fits this model exceptionally well - when used correctly.
High-Level Architecture
Terraform (Git)
|
|-- Network primitives
|-- Cluster lifecycle
|-- IAM & access boundaries
|
Remote State (Locking + Audit)
Terraform is not just provisioning infra - it becomes the contract between platform and application teams.
Repository Structure (Designed for Scale)
platform-infra/
├── modules/
│ ├── network/ # opinionated, versioned
│ ├── kubernetes/ # cluster lifecycle only
│ ├── iam/ # least-privilege boundaries
├── environments/
│ ├── dev/
│ ├── uat/
│ └── prod/
├── backend.tf # remote state + locking
├── versions.tf
└── provider.tf
Why this matters
- Modules are immutable contracts
- Environments only supply inputs, never logic
- Changes become reviewable deltas, not surprises
Kubernetes Module: What Terraform Should (and Shouldn't) Do
Terraform should:
- Create clusters
- Define node pools
- Enforce baseline security
- Configure networking
Terraform should not:
- Deploy applications
- Manage runtime scaling
- Handle per-service configuration
That boundary keeps the platform stable.
Cluster Definition (Intentional Minimalism)
resource "google_container_cluster" "this" {
name = var.cluster_name
location = var.region
remove_default_node_pool = true
initial_node_count = 1
release_channel {
channel = "REGULAR"
}
workload_identity_config {
workload_pool = "${var.project_id}.svc.id.goog"
}
}
Why this matters
- Release channels reduce operational burden
- Workload Identity eliminates long-lived secrets
- Default node pools are avoided by design
Node Pools as Failure Domains
resource "google_container_node_pool" "system" {
name = "system-pool"
cluster = google_container_cluster.this.name
node_config {
machine_type = "e2-standard-4"
labels = {
workload = "system"
}
}
autoscaling {
min_node_count = 1
max_node_count = 3
}
}
This enables:
- Workload isolation
- Predictable blast radius
- Safer upgrades
Environment Parity via Inputs
cluster_name = "platform-prod"
region = "asia-south1"
node_min = 3
node_max = 10
Same code. Different intent.
Operational Outcomes
- Deterministic infrastructure
- Reproducible environments
- Faster incident recovery
- Safer experimentation
Terraform becomes boring - and that's a compliment.
Enjoyed this architecture deep-dive?
Discuss Platform Engineering